Evaluation occurs in real-world contexts, which means that we often don’t have as much control as we do in research projects. For example, in research we may be able to randomize participants to receive an intervention or not, whereas randomization might not be possible in the real world. And even having a group that doesn’t get the intervention might not be possible . At the same time, we want our evaluations to be as rigorous as possible given our circumstances, so that we can have the best results possible. After all, if we are doing an evaluation to find out what’s working and what isn’t working well, we want the answers to those questions to be accurate so that we can make our programs as effective as possible. And if we are doing our evaluation to make a summative judgement, (such as “this program works and should be continued/rolled out to other settings” or “this program does not achieve its objectives, so needs to be fixed or stopped”), we want that answer to be correct too. Figuring out what evaluation design to use in a given situation involves determining what designs will work in our circumstances and thinking about how to maximize the validity and power. While trying to do just that for an evaluation I’m currently planning, I came across a couple of articles that summarize some designs that can be used when we have small sample sizes and I thought it would be worth describing them here.
Randomized controlled trials (RCTs) are generally thought of as the “gold standard” for evaluating effectiveness of interventions. They have the advantages that:
- being a prospective design where the researcher is manipulating a variable of interest, you can attribute causation to your results
- being randomized reduces biases, such as having different characteristics of the intervention and control group resulting from allowing people to select which group them go in (or having some other reason why the members of groups are selected)
- if they are double-blinded (i.e., neither the researcher measuring the results nor the participants know who is getting the intervention an who is in the control group), they reduce bias that could result from people expecting the intervention to work better than control
However, there are some reasons why you might not be able to use an RCT design:
- If there are only a small number of people in the population of interest or it is extremely expensive to implement, resulting in only being able to access a small number of participants, then you will not have much statistical power to detect an effect.
- If you have to implement the intervention to a group (instead of to individuals), and you can only have a small number of groups (since the “group” would be the “unit of analysis”), you wouldn’t have much statistical power.
- It might not be culturally acceptable to randomize some individuals or groups to not receive a services (e.g., in some Aboriginal cultures).
- If the community has decided they want to implement a program to everyone even though they don’t yet have evidence of efficacy.
- It could be that the intervention has been shown to work in other places, so they have confidence that it will work in their situation, but they want to an evaluation to find out if this is true.
- The community has already implemented the intervention and now want to evaluate if the program is achieving its intended goals.
So what do you do in these cases? Fortunately, there are some research designs that can help deal with some of these issues. The rest of this posting will discuss four of them: Dynamic Wait-Listed Design, Regression Point Displacement Design, Stepped Wedge Design, and Interrupted Time-Series Design .
Dynamic Wait-Listed Design (DWLD)
- a randomized design in which:
- participants/groups are randomized to receive an intervention right away or starting at one of a number of future time points
- groups can be balanced into equivalent blocks and the blocks are randomized
- the groups not yet receiving the intervention (i.e., on the “wait list”) serve as controls for those who are receiving it
- everyone receives the intervention by the end of the study
- outcome of interest is measured at all the time points throughout the study
- pros:
- increases statistical power compared to traditional wait list design (in which participants/groups randomized to either “receive intervention now” or “receive intervention later” groups; more time during which to compare the intervention to control (i.e., during traditional wait list design, once the wait list starts to receive the intervention, you no longer have anyone in the control group to compare to the intervention group).
- Have data on almost all units from before, during initial adoption of intervention, and after adoption, so can “compare intervention impact across units and across time.” (Wyman et al, 2014)
- increased internal validity (compared to traditional wait list design) because shorter wait time = less likely that participants will seek out another intervention
- multiple groups make it less like that a major historical event will affect the data (compared to having only 2 groups in a traditional wait list (or even an RCT))
- randomization makes the design “less susceptible to readiness to participate or other biases” (Wyman et al, 2014)
- by increasing the number of groups (compared to traditional wait list design), external vality is increased
- reduced risk of being affected by historical events, increases internal validity
- cons:
- cannot double blind (as there’s no way for wait list group to not know they are ton the wait list), so does not control for placebo effect
- those on the wait list may seek out other inventions because they know they are on the wait list.
- can only evaluate time-limited effects
- useful when: it has been decided that everyone will get the intervention/it is felt that it is unethical/unacceptable to leave some people/groups in a no-intervention group
- adaptations to this method:
- pairwise enrollment DWLD: you “start with a small number of units and “grow” a randomized trial over time by cumulating small numbers of randomized wait-listed studies”(Wyman et al, 2014)
- select 2 units and randomize one to “invention now” and one to “wait list”
- record outcomes of interest during the first time interval, but don’t record anything after that (i.e., when second group starts to get intervention
- repeat with more pairs until you have sufficient statistical power to detect a difference
- single selection DWLD:
- select 2 units and randomize one to “invention now” (group 1) and one to “wait list” (group 2)
- record outcomes of interest during the first time interval
- randomly select a third group (group 3) from the wait list to serve as the next “control” group and start intervention with group 2 (the first wait listed group)
- both pairwise and single selection DWLD do not have as much longitudinal data as DWLD (since you stop tracking data for groups getting the intervention after one time interval), they have less statistical power than DWLD
Regression Point Displacement Design (RPDD)
- a quasi-experimental design for “evaluation of prevention programs conducted with a single intervention unit or a very small number of intervention units, when archival data for multiple units from the same population prior to and following implementation of the intervention are available” (Wyman et al, 2014)
- a variation of the regression discontinuity design (RDD)
- get archival data from units that haven’t received the intervention and use them to create an “expected” post-test score, which you can then compare to the actual post-test score for the unit receiving the intervention
- the “more the selection process approximates random selection, the more valid with be the causal inference” (Wyman et al, 2014), though usually the intervention unit(s) aren’t chosen randomly (e.g., they are often chosen best on the setting with the most need or the setting that is most willing or most ready)
- can use propensity scores to mitigate this
- theoretically, you can use any unit of analysis, but you should choose the unit of analysis that:
- is “sized to maximize the pretest-posttest correlation” (Wyman et al, 2014)
- have available data for before and after the intervention is implemented
- pros:
- increased statistical power when you have a high correlation between pre-test and post-test scores (compared to studies that only have one or a few settings but don’t use RPDD)
- cons: not randomized (so cannot attribute causation)
- can use of propensity scores to mitigate
- useful when: an implementation has already been planned or even already been implemented and when settings are not randomly selected (e.g., due to logistics, ethics, and/or cultural norms)
Stepped Wedge Design (SWD)
- a longitudinal design in which group receives the baseline (i.e., wait-listed control) condition and the intervention condition, with the time at which each group crosses over from baseline to intervention being randomized
- every group eventually gets the intervention and once a group is getting the intervention, they continue to get it (i.e., it is not withdrawn)
- the outcome of interest is measured at all time points and you compare the group(s) in the control condition to the group(s) in the intervention condition at each step of the wedge
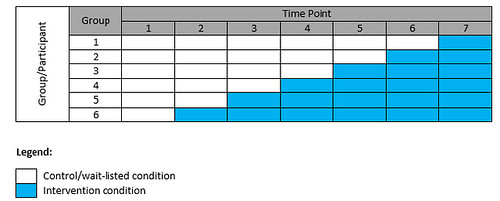
- to analyze a SWD, you use “a linear mixed-effects model that includes fixed effects for time and for intervention status at each particular time point” (Fok et al, 2015)
- pros:
- statistical power is:
- related to number of time points and number of participants/groups randomized at each step
- maximized when you randomize each group/participant to its own time step
- reduced risk of being affected by historical events, increases internal validity
- cons:
- if your intervention is such that increased dosage –> strong effect, you might get a reduced ability to show an effect because those who are randomized to the later time points won’t have the intervention for very long (though you can increase the number of time points at which you measure to offset this a bit)
- dose differs by groups, and some groups have to wait a long time
- longer duration of the study
- risk of contamination between those in the intervention part of the wedge and those in the control part
- cannot blind participants to which part of the wedge they are in
- useful when:
- you believe the intervention will do more harm than good “rather than a prior belief of equipoise” (Brown & Lilford, 2006), so it would be unethical to withhold the intervention from the control group (as in a RCT) or to withdraw the intervention (as in a cross-over design) – e.g., when a program has been shown to be effective in another setting and you want to know if it is also effective in your setting
- you are unable to provide the intervention to all groups at once (e.g., due to logistical, practical, or financial constraints)
- random allocation can be seen as an ethical way to decide who gets the intervention when
Interrupted Time-Series Design (ITSD)
- time series = multiple observations/values of a measurement are taken over a period of time
- interrupted time-series design (ITSD) = multiple observations taken over time both before and after the intervention with the same group/participant
- “interrupted” refers to the introduction of the intervention, thus dividing the time series into segments
- there can be multiple groups that are getting the intervention and the time at which their baseline and intervention phases begin can be the same or differentsimplest form: A-B design (multiple observations in baseline (A), then multiple observations in intervention phase (B)).
- reversal (or withdrawal) design: can introduce and then withdraw the intervention (A-B-A), with multiple observations in each phase; this can be extended (ABAB, ABABAB, etc.)
- segmented regression analysis can be used to analyze ITSD
- pros:
- you compare the pre-post from the group to determine the intervention affect – this has the benefit of having the group/participant serve as their own control, so you don’t need to work about pre-existing differences across groups or about cross-contamination of the control group from the intervention group
- statistical power increases with increasing number of observation
- cons:
- potential for seasonality effects or historical events to affect the results
- for withdrawal design, if the effects of the intervention persist after intervention, would contaminate the subsequent “B” phases
- requires a lot of measurements points, high cost, potential high participant burden
Some other commentary:
- Brown et al (2009) (cited in Wyman et al, 2014) recommend calling DWLD and SWD “roll-out designs where (1) all units eventually receive the intervention, (2) the timing of units to receive the intervention is determined equitably (i.e., randomization), and (3) the design is used to evaluated effectiveness as an intervention is rolled out.”
- those who receive intervention first may benefit from receiving it first, but those who receive it later may benefit because the intervention may be improved by feedback on the earlier implementations of the intervention being used to improve the intervention
- another type of roll-out design: all units are wait-listed and then “at a random time they are randomly assigned to one of two alternative interventions”, which are then compared “head-to-head”
References: