I’m falling down a rabbit hole of reading on this topic! Here are some notes on more papers I’ve read lately… and there will be more (as again, this posting got quite long, so I’m just posting it now and will start another blog posting for the other articles I’m reading on this topic!)
Applying complexity theory: A review to inform evaluation design
- this paper uses “complexity” to refer to “understanding the social systems within which interventions are implemented as complex” (p. 119)
- he defines a complex system as “comprised of multiple interacting actors, objects and processes define as a system based on interest or function” and “are nested”. “The interaction of components in a complex system gives rise of ’emergent’ properties, which cannot be understood by examining the individual system components” and “interactions are non-linear” (p. 119)
- “challenges posed by complex social systems for evaluation relate to uncertainty in the nature and timing of impacts arising from interventions, due to non-linear interactions within complex systems and the ’emergent’ nature of system outcomes. There are also likely to be differing values and valuation of outcomes from actors across different parts of a complex system, making judgements of ‘what worked’ contested.” (p. 120)
- “due to the open boundaries of complex systems, there are always multiple interventions operating and interacting, creating difficulties identifying the effects of one intervention over another” (p. 120)
- in the literature, “there is little consensus regarding what the key characteristics of a complexity informed policy or program evaluation approach should be” (emphasis mine, p. 120)
- this review paper identified the following themes:
- developing an understanding of the system
- “the need to develop a picture of the system operating to aid analysis of both interaction and of changes in system parts” (p. 121)
- “boundaries are constructs with decisions of inclusion and exclusion reflecting positions of actors involved in boundary definitions” (i.e., “boundaries likely reflect the interest of evaluators and others defining evaluation scope”) (p. 121)
- “complex system boundaries are socially constructed, so we should be asking about what systems are being targeted for change and what ‘change’ means to various people involved” (p. 125)
- attractors, emergence, and other complexity concerns
- emergent properties: “generated through the operation of the system as a whole and cannot be identified through examining individual system parts” (p. 123)
- this challenges the role of evaluating predetermined goals
- attractor states: “depict a pattern of system behaviour and represents stability, with a change in attractor state representing a qualitative shift in the system, with likely impacts on emergent phenomena” (p. 123)
- it’s important to keep “a holistic view of the system over long time periods” (p. 123)
- emergent properties: “generated through the operation of the system as a whole and cannot be identified through examining individual system parts” (p. 123)
- defining appropriate level of analysis
- the literature includes “a clear call for evaluation to focus upon multiple levels, whilst also noting the challenge this creates” (p. 123)
- timing of evaluations
- “non-linear interactions and potential for sudden system transformation suggest we cannot predict when the effects of an intervention will present. Therefore, long evaluative time frames may be required” (p. 123)
- “evaluation should, if possible, occur concurrently alongside programme development and implementation” (p. 123)
- but long timeframes “pose a challenge to the question of what should be evaluated” and “suggest that evaluative activity needs to be on going and that the line between evaluation and monitoring may be blurred. Attribution of outcomes to specific interventions becomes more complicated over time with the number of local adaptations, national level policy changes, and social and economic contextual changes likely to increase.” (p. 123)
- there is a “role of evaluation for understanding local adaptations and feeding back into implementation processes” (p. 123) – and this “may be more immediate and relevant to current implementation decisions [than a focus on outcomes/attribution] and therefore provide a more tangible focus for evaluation” (p. 123)
- participatory methods
- “used to gather perspectives of actors across the system to develop systems descriptions; understand how interventions are adapted at the local level; and make explicit different value claims of actors across the system” (p. 124)
- case study and comparison designs
- pro: “ability to develop a detailed understanding of a system (or a limited number of systems), in line with complexity theory concepts” (p. 124)
- multiple and mixed methods
- “a logical response to the challenge of providing contextualised information on what works” (p. 124)
- layering theory to guide evaluation
- “multiple theories can be nested for explanation at multiple levels of a system” (p. 124)
- developing an understanding of the system
- “participation build into the evaluation from the start, and a close relationship with stakeholders throughout the evaluation lifecycle is part of an ‘agile’ evaluation” (p. 125)
Perturbing ongoing conversations about systems and complexity in health services and systems
- “What matters is making sense of what is relevant, i.e., how a particular intervention works in the dynamics of particular settings and contexts” (p. 549)
- “the most useful questions addressing complex problems must imply an open system: ‘What will the intervention be able to produce? and ‘What kind of behaviour will emerge? What are our frames of reference? What are our ideas and values in relation to success?’ (Stengers cited on p. 549)
- “Frameworks for understanding policy development do not merely describe the process. They invariably indicate what a “well-functioning” process is like. And so they place a value on certain structures and behaviour. As our theories change, so do our vies of what is good” (Glouberman cited on p. 549)
- “common to complex systems are two fundamental themes:
- the universal interconnectedness and interdependence of all phenomena
- the intrinsically dynamic nature of reality” (p. 549)
- although there seems to be lots of talk about complexity, its “uptake” in health systems/services has been slow
- “reductionism remains the dominant paradigm”
- we often break down the work of clinicians into “discrete activities based on a business model drive by the agenda of cost containment rather than improved patient health” (p. 550)
- “we must counterintuitively work to develop appropriate abstract frameworks and categories, and reflect on our ways of knowing, if we are to gain a deeper understanding of the processes that operate in complex systems, and how to intervene more successfully” (p. 550)
- “the awareness of complexity does not imply answering questions or solving problems: rather, it means opening problems up to dynamic reality, as well as increasing the relative level of awareness. Thus, the notion of complexity […] strongly supports the possibility that […] questions and answers may change, as well as the nature of questions and answers upon which scientific investigation is built” (p. 551)
Theory-based Evaluation and Types of Complexity
- “evaluation deficit” – “the unsatisfactory situation in which most evaluations, conducted at local and other sub-national levels, provide the kind of information (on output) that does not immediate inform an analysis of effects and impacts at higher levels, i.e., whether global objectives have been met. Or, conversely, impact assessment is not corroborated by an understanding of the working of programmes.” (p. 59)
- Stame criticizes “mainstream evaluation” for “choosing to play a low-key role. Neither wanting to enter into the ‘value’ problem […], nor wanting to discuss the theoretical implications of programmes, evaluators have concentrated their efforts on developing a methodology for verifying the internal validity (causality) and external validity (generalizability) of programmes” (p. 59). She goes on to list the consequences of this “low-key” approach:
- “fail to formally or explicitly specify theories”
- assuming the programs are “rational” – e.g., “assuming the needs are know, decision makers are informed […], decisions are taken with the aim of maximizing gains from existing resources”
- since programs are seen as “rational”, “politics was seen as a disturbance or interference and the political context itself never became an object of inquiry”
- thinking of the outcome of evaluation as being just “‘instrumental’ use: saying that something worked or did not work” (p. 60)
- theory-oriented evaluations:
- “changes […] the attitude towards methods” … “All methods can have merit when one puts the theories that can explain a program at the centre of the evaluation design. No method is seen as the ‘gold standard’. Theories should be made explicit, and the evaluation steps should be built around them: by elaborating on assumptions; revealing causal chains; and engaging all concerned parties” (p. 60)
- some different approaches to theory-oriented evaluations:
- Theory-driven evaluation (Chen & Rossi) – many programs have “‘no theory’, goals are unclear, and measures are false”, so “evaluations are ‘at best social accounting studies that enumerate clients, describe programs, and sometimes count outcomes”. “The black box is an empty box.” Thus, their approach is “more to provide a programme’s missing theory than to discuss the way programmes exist in the world of politics” (p. 61).
- Theory-based evaluation (Weiss) – the “black box is full of many theories […that] take the form of assumptions, tacit understandings, etc: often more than one for the same programme.” (i.e., different people involved – the many program implementers, recipients, funders, etc. – may all be operating based on different ideas of how the program works and may not even be aware of their own theories. Two parts to theories of change (1) “‘implementation theory,” which forecasts in a descriptive way the steps to be taken in the implementation of the programme” and (2) “‘programmatic theory’, based on the mechanisms that make things happen” (p. 61-62)
- Realist Evaluation (Pawson & Tilley): they “stress what the components of a good programme theory should be: context (C) and mechanism (M), which account for outcome (O). Evaluation should be based on the CMO configuration. Programmes are seen as opportunities that an agent, situated inside structures an organizations, can choose to take, and the outcomes will depend on how the mechanism that is supposed to be at work will be enacted in a given context.” “We cannot know why something changes, only that something has changed […] in a given case. And that is why it is so difficult to say whether the change can be attributed to the programme. The realist approach is based on a ‘generative’ theory of causality: it is not programmes that make things change, it is people, embedded in their context, who, when exposed to programmes, do something to activate given mechanisms, and change. So the mystery of the black box is unveiled: people inhabit it.” (p. 62)
- similarities among these theory-oriented approaches:
- evaluation is based on “an account of what may happen”
- they “consider programmes in their context”
- use “all methods that might be suitable”
- “are clearly committed to internal validity (they indeed look for causality), but nonetheless allow for comparisons across different situations” (p. 63)
- differences among these theory-oriented approaches: role of theory, role of context
- “reality is complex because:
- it is stratified, and actors are embedded in their own contexts; and
- each aspect that maybe be examined and dealt with by a programme is multifaceted” (p. 63) [this doesn’t seem to fit any of the other definitions of “complexity” that I’ve read]
- “if […] the evaluator considers that what is important is to know how impact has been attained and why, s/he is bound to consider that means […] are relevant. Evaluation is then concerned with different ways of reaching objectives, and tries to judge which policy instruments, in isolation or in combination, and in what sequence, are better suited to the actors situation in given contexts” (p. 66)
Complex, but not quite complex enough: The turn to the complexity sciences in evaluation scholarship
- This article provides a critique to the way that many evaluators have been writing about, and attempting to apply, “complexity sciences” (see my previous posts here and here for my notes from some of the types of articles he’s critiquing)
- Mowles’ main critiques are that:
- “there is a tendency either to over-claim or under-claim [the] importance” (p. 160) of complexity sciences
- evaluation “scholars are not always careful about which of the manifestations of the complexity sciences they are appealing to” (p. 160)
- evaluation scholars do not always “demonstrated how they understand [the complexity sciences] in social turns” (p. 160)
- evaluators who favour a “contingency approach to complexity” (i.e., we can pick and choose when to use it based on our decision about if a program (or part of a program) is “complex”) “suggest complexity is a ‘lens’ or framework to be applied if helpful, and take emergence to mean the opposite of being tightly planned” (p. 167). This leads to evaluators seeing only those programs (or parts of programs) that they have deemed to be complex as “need[ing] “a special and “trying to feed back data and information in real time” (p. 167)
- But “in portraying emergence as a special phenomenon [these evaluators] have implicitly dismissed the idea that the human interaction is always complex, and that emergence, which we might understanding in social terms as the interplay of intentions, is always happening, whether a social program is tightly planned or not” (p. 167)
- thus, “complexity sciences” are used as just another tool within evaluation as a “logical, rational activity” (p. 160) – he cites Fleck who “described the ways in which groups of scholars, committed to understanding the world in a particular way, resist the rise of new ideas by either ignoring them or rearticulating them in terms of the prevailing orthodoxy” (p. 161) – with the implication being that this is what many evaluators are doing – rather than grappling with the complexity sciences to see what the implications are for evaluation, they are trying to fit the complexity sciences into their existing ways of evaluating. He goes on to ask “what difference appealing to the complexity sciences makes to the prescriptions that scholars recommend for evaluative practice” (p. 161). – that is, does “applying” complexity theory lead these evaluators to do anything differently than they would have done without it?
- trends noted in evaluation scholarship re: complexity:
- many suggest that complexity is something that an evaluator should choose at what time/in what circumstances to use
- many use the “Stacey Matrix” which and which is “a contingency theory of organizations understood as complex adaptive systems [that] suggests that the nature of the decision facing managers depends on the situation facing them” (p. 163) [The one Patton uses in his Developmental Evaluation book – with low-high certainty on one axis and low-high agreement on the other and you use it to determine if something is simple, complicated, complex, or chaotic] – even though “Stacey himself abandoned the idea that organizations can be helpfully understood as complex adaptive systems, and has moved on from a contingency perspective” (p. 163)
- using this approach “allows evaluators in the mainstream to claim that the complexity sciences may be quite helpful but only in circumstances of their own choosing” – this represents the “‘spectator theory of knowledge’, which sustains a separation between the observer and the thing observed.” (p. 164)
- Mowles suggests that everything is complex “even following rules like a recipe [the oft given example of “simple”] “is a highly social process where the rules inform practice and practice informs the rule” (p. 163)
- talking about “complexity sciences” as if it were just one thing, “homogenizing” them OR just picking “some of the characteristics of particular manifestations of the complexity sciences” (p. 162) [thought: it’s kind of funny that complexity theory includes the notions that the whole is not just the sum of the parts/you can’t understand the whole just by looking at the parts… but then we say we are applying complexity theory by just looking at some of the parts]
- he notes that Patton draws on a lot of aspects of complexity sciences for his Developmental Evaluation approach “without offering a view as to whether one particular branch of the complexity sciences is more helpful than another” (p. 164)
- he also notes, somewhat snarkily (though not unjustifiably) in my opinion, that “In the development of the disciplines of evaluation, particularly those claiming to be theory-based, it is probably important to know what the theories being taken up actually claim to be revealing about nature, and to be able to make distinctions between one theory and another” (p. 164)
- making the assumption that “the social is best understood in systemic terms”; social/health interventions understood as a “system with a boundary, even if that boundary is ‘open’. Interaction is then understood as taking place between entities, agenda, even institutions operating at different ‘levels’ of the system, or between systems, which leads to the idea that social change can be both wholesale and planned”….. this “allows scholars to avoid explaining their theory of social action, or to interpret complexity theories from the perspective of social theory and thus to read into them more than they sustain” (p. 162)
- many suggest that complexity is something that an evaluator should choose at what time/in what circumstances to use
- “insights from complexity theory help us understand why social activity is unpredictable”, but remember that “evaluation practice […] is also a social activity”, so “it can no longer be grounded in the certainties of the rational, designing evaluator” (p. 163)
- a brief summary of how complexity theory evolved over time:
- Step 0: equilibrium model in classical physics & economics that assumes
(a) system with a boundary, made of interacting entities
(b) entities are homogeneous
(c) interactions occur at an average rate
(d) system moves towards equilibrium - Step 1:
- removes assumption (d) (i.e., not assumed to be moving towards equilibrium)
- replaces linear equations with non-linear
- output of one equation feeds into next iteration of the equation
- basis for modeling chaos
- Step 2:
- removes assumptions (c) (i.e., interactions not assumed to occur at an average rate) and (d) (i.e., not assumed to be moving towards equilibrium)
- used to explain dissipative structures, things jumping to different states, ability of things to self-organize
- Step 3:
- removes assumptions (b) (i.e., entities are not homogeneous), (c) (i.e., interactions not assumed to occur at an average rate) and (d) (i.e., not assumed to be moving towards equilibrium)
- Step 0: equilibrium model in classical physics & economics that assumes
- complex adaptive systems (CAS) – “agent-based models run on computer” are “temporal models that change qualitatively over time and attempt to explain how order emerges from apparent disorder, without any overall blue-print or plan” (p. 165)
- attempts “to describe how global patterns arise form local agent behaviour” (p. 166)
- can operate at Step 2 or 3
- in real life, people are not homogenous and interactions are not average and not linear, so it is at Step 3 where we see “truly evolutionary and novel behaviour emerge” (p. 166)
- “models are helpful in supporting us to think about real world problems, [but remember that…] “mathematical models uncover fundamental truths about mathematical objects and not much about the real world” (p. 166)
- Mowles identifies three evaluation scholars (Callaghan, Sanderson, Westhorp) who suggest that evaluators should “draw on insights from the complexity sciences more generally to inform evaluation practice, rather than understanding the insights to refer only to special cases” (p. 167)
- he identifies that the use of experimental methods to evaluate represents the “highest degree of abstraction” (p. 167) from the program being evaluated and notes that “Theories of Change” are a “hybrid of systems thinking and emancipatory social theory” (p. 168) as they “draw on propositional logic and represent social change in the form of entity-based logic models showing the linear development of social interventions towards their conclusions” (p. 167), but also “often point to the importance of participation and involvement of the target population of programmes to inspire motivation” (pp. 167-8)
- “realist evaluators” talk of “‘generative’ theories of causality, i.e., ones that open up the ‘black box’ of what people actually do to make social programmes ‘work’ or not” (p. 168) – they argue that “interventions do or do not achieve what they set out to because of a combination of context, mechanism and outcomes (CMO). [RE] is concerned with finding what works for whom and in what circumstances and then extrapolating a detailed and evolving explanation to other contexts” (p. 168)
- Callaghan “adds […] on the idea of a mechanism, that what people are doing locally in their specific contexts to make social projects work is to negotiate order” (p. 168)
- Westhorp “recommends trying to identify the local ‘rules’ according to which people are operating as a way of offering richer evaluative explanations of what is going on” (p. 168)
- but Mowles suggests that this does not go far enough and that rather than opening the black box, realist evaluators “use a mystery to explain a mystery” (p. 168) and don’t seem able “to let go of the idea of a system with a boundary, outside which the evaluator stands, comprising abstract, interacting parts” (p. 169)
- he also suggests that the “persistence of systematic abstractions and predictive rationality may be that they protect the discipline of evaluation by separating the evaluator from the object to be evaluated” (p. 169) – not that evaluators are totally “unaware of the way that they influence social interventions” (p. 169), but that they “only go so far in developing how much these non-linear sciences apply to them and what they are doing in the practice of evaluation” (p. 170)
- Mowles’ suggested alternative is “a radical interpretation of the complexity sciences, which understands human interaction as always complex and emergent” (p. 160)
- he references Stacey (remember, the one who has moved on from the contingency approach) and colleagues and notes that “they argue that in moving form computer modelling [e.g., CAS] to theories of the social, but by preserving some of the insights by analogy, it might be helpful to think of social interaction as tending neither towards equilibrium nor as linear, nor as forming any kind of a whole. Social life always takes place locally between diverse individuals who have their own history and multiple understandings of what is happening as they engage and take up broader social themes” (p. 170)
- he goes on to say that rather than thinking in terms of a system with a boundary, we think of “global patterns of human relating aris[ing[ from many, many local interactions, paradoxically informing and informed by […] the habitus. The habitus is habitual and repetitive, but because it is dynamically and paradoxically emerging it also plays out in surprising, novel and sometimes unwanted ways because of the interweaving of intentions.”
- Mowles discusses the following implications for evaluation of his “radical” interpretation of complexity:
- evaluators cannot really just “decide” which social interventions (or parts thereof) are complex and which ones are not
- “calls into question the idea that emergence is a special category of social activity” (p. 171) – “social life is always emerging in one pattern or another, whether an intervention is tightly or loosely planned, and that people are always acting reasonably […] rather than rationally” (p. 171)
- “evaluation is a situated, contextual practice undertaken by particular people with specific life-histories interacting with specific others, who are equally socially formed. The evaluative relationship is an expression of power relations, both between the commissioner of the social intervention/evaluation and the evaluator, and between these and the people comprising the intervention, which will inform how the evaluation emerges” (p. 171)
- simplifying programs for the purposes of evaluation “cover[s] over the very improvisational and adaptive/responsive activity that makes social projects works, and even improve them, and which should be of interest both to commissioners and evaluators” (p. 171)
- “an evaluator convinced about complexity might […] take an interest in how their own practice forms, and is formed by the relationships they are caught up in with the people they are evaluating” (p. 171) – they’d be interested in:
- “how people in the intervention negotiate order” (p. 171)
- “how the evaluation itself is negotiated” (p. 171)
- “how power relations play out in, and affect, the social intervention, including the framing of both the social development project as a logical project and the evaluation as a rational activity” (p. 171)
- “pay[ing[ close attention to the quality of conversational life of social interventions, including how participants took up and understood any quantitative indicators that they might be using in the unfolding project” (p. 171)
- “there will always be unintended and unwanted outcomes of social activity, which may be just as important as what is intended” (p. 171)
- “how the programme changed oer time, and how people accounted for these changes: ‘progress’ in terms of the social intervention, could also be understood in the movement of people’s thinking and their sense of identity” (p. 171)
- “evaluators should assume a greater humility in their work and their claims about predictability, causality and replicability” (p. 171)


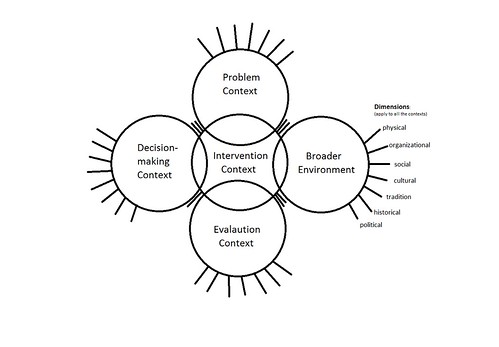
 Context Assessment: Areas of Context That Affect Evaluation Practice
Context Assessment: Areas of Context That Affect Evaluation Practice