
In September, I had the fantastic opportunity to attend the Australasian Evaluation Society conference in Perth, Western Australia. As I did with the Canadian Evaluation Society conference, I’m going to summarize some of my insights, in addition to cataloguing all the sessions that I went to. So rather than present my notes by session that I went to, I’m going to present them by topic area, and then present the new tools I learned about. Where possible. I’ve included the names of people who said the brilliant things that I took note of, because I think it is important to give credit where credit is due, but I apologize in advance if my paraphrasing of what people said is not as elegant as when the people actually said them. I’ve also made notes of my own thoughts, as I was going through my notes to make this summary, which I’ve included in [square brackets]
Evaluation
- Traditionally, evaluation has been defined as being about judging merit or worth; a more contemporary view of evaluation includes it being about the production of knowledge, based on systematic enquiry, to assist decision making. (Owen) [This was interesting to me, as we have been working on elucidating the differences/overlaps among evaluation, research, monitoring, quality improvement, etc. Owen’s take on evaluation further blurs the line between evaluation and research, as research is often defined as producing new knowledge for knowledge’s sake.]
- Evaluation is “the handmaiden of programs” (Owen) – what really matters is the effective delivery of programs/policies/strategies. Evaluation being involved on the front-end has the most potential to help that happen.
- I really like this slide from John Gargani, the American Evaluation Association president:

Theory vs. Practice
- Practice is about actually doing something vs. theory, which is about having “coherent general propositions used as principles of explanation for a class of phenomena or a particular concept of something to be done or of the method of doing it; a system of rules or principles” (Owen).
- Praxis: “the act of engaging, applying, and reflecting upon ideas, between the theoretical and the practical; the synthesis of theory and practice without presuming the primacy of either” (Owen).
Evaluative Thinking (ET)
- ET is a form of higher order thinking: making judgments based on evidence, asking good questions, suspending judgment in the absence of sufficient evidence, etc.
- “If I know why I believe X, I’m relatively free to change my belief, but if all I know is “X is true”, then I can’t easily change my mind even in the face of discomfirming evidence” (Duncan Rintoul).
Evaluation-Receptive Culture
- Newcomer, citing Mayne (2010), talked about the features of an “evaluation-receptive culture”:
- fight the compliance mentality [looking only to see if people are complying with a state program/procedure pre-supposes that the it is the “right” program/procedure – evaluation does not make such presuppositions]
- reward learning from monitoring and evaluation
- cultivate the capacity to support both the demand for, and supply of, information
- match evaluation approaches/questions with methods
Evaluation and Program Planning
- evaluative thinking and evaluation findings can be used to inform program planning (note that this isn’t always what happens. Often program planning is not as rational of a process as we’d hope!)
- “proactive evaluation” (according to Owens et al) = we need to know:
- what works: what interventions –> desired outcomes
- practice: how to implement a program
- who to involve
- about the setting: how contextual factors affect implementation
- innovation factors affecting program design:
- implementation is the key process variable, not adoption [where they used “adoption” to mean “choosing the program”. My experience is that this is not how the word “adoption” is always used 1E.g., while Owen used “adoption” to refer to the “adoption” (or choosing) of a program to implement, I’ve seen others use “adoption” to refer to individuals (e.g., to what extend individuals “adopt” (or enact) the part of their program they are intended to enact).
- the more complex the intervention, the more attention needs to be given to implementation
- we need to analyze key innovation elements, with some elements needing more attention than others
- the most difficult element to implement are changed user roles/role relationships
- change is a process, not a single event
- when implementing a program at multiple sites, there will be variation in how it is implemented
- there must be effective support mechanisms and leadership buy-in is essential
- evaluation tends to be more context sensitive than research [I’d qualify this with “depending on the type of research”]
- why do people not include context sensitivity in complex intervention design?
- command and control culture (with a lack of trust in the front lines)
- structural limitations of processing and responding to large amounts of data with nuanced implications
- epistemologies, especially in the health sector (where people tend to think that you can find an intervention (e.g., drug, surgery) that works and then push out that intervention, despite the evidence that you can’t just push out an intervention and expect it will be used)
- profound differences between designers and intended users – evaluators can “translate” users voices to designers
Evidence-Based Policy
- the theory of change of evidence-based policy :
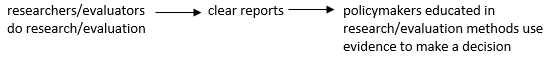
- “evidence-based” policy can refer to any of these levels:
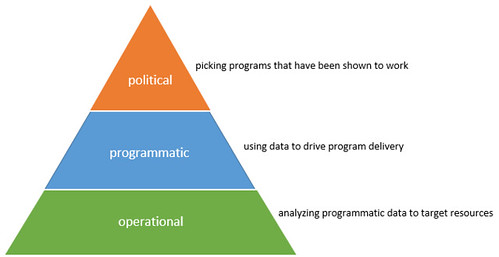
- some challenges for evidence-based policy:
- what constitutes “evidence”?
- is evidence transferrable? (e.g., if it “works” in a given place and time, does that necessarily mean it will work in another place or at another time?)
- people often overstate the certainty of the evidence they collect – e.g., even if a study conclusion is that a program played a causal role in the place/time they was conducted, will it play a wide enough casual role that we can predict it will play a causal role in another time/place (which is what “evidence-based” policy is doing when it takes conclusions from a study/studies as evidence that the program should be applied elsewhere)?
Rubrics
- problem: to make evaluative conclusions, you need standards to make those conclusions
- most evaluation reports do not provide specifics about how the evaluation findings are synthesized or the standards by which the conclusions are drawn (often they do this implicitly, but it’s not made explicit
- this lack of transparency about how evaluation conclusions are drawn makes people think that evaluation is merely subjective
- rubric comes from “red earth” (used to mark sheep to track ownership and breeding)
- the nature of evaluation (Scriven):

- the logic of evaluation, summarized in 4 steps:
- establish criteria
- construct standards
- measure performance
- compare performance to standards and draw conclusions
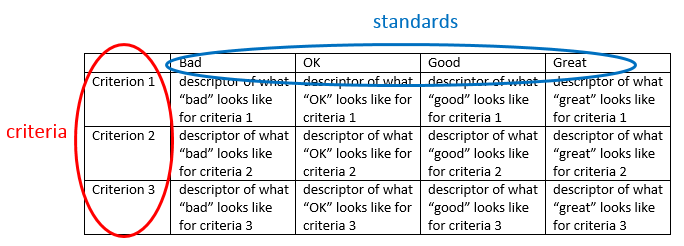
- you compare your performance data to the descriptors to determine whether the standard was achieved, which allows you to draw an evaluative conclusion [I am familiar with rubrics from my work as an instructor, where I often provide grading rubrics to my students so that they know what level of work I am expecting in order to get an A, B, C, D, or F on an assignment. I haven’t yet used a rubric in a program evaluation]
- by determining the standards before you collect performance data, you are thinking about what does a “good” or “successful” program look like up front; if you only start to think about what is good enough to be considered success after you see the data, you can be swayed by the data (e.g., “Well, this looks good enough”)
- use the literature and stakeholders to build your rubrics
- Martens conducted a literature review and interviews and found that few evaluators write about using rubrics in their work (not clear if it’s because people aren’t using them or just aren’t writing about them) and that most people who use them learned through contact with Jane Davidson or her work
- it was noted that because of the transparency of rubrics, people don’t argue about whether measures are “good enough” (like they did before that person used rubrics)
- rubrics do need to be flexible to changing evaluand – it was also noted that sometimes evidence emerges during an evaluation that you hadn’t planned for in your rubric – and it’s OK to add, for example, a new criteria; but you can’t change the rubric after the fact to hide something on which the program did poorly
- future research is needed on best practices for using rubrics and to investigate the perspectives of funders and evaluation users on rubrics
Implementation Science
- implementation = “a specific set of activities designed to put into place an activity or program of known dimensions” (Fixsen eta l, 2005; cited by Wade)
- this table provides a nice distinction between what we typically evaluate in program evaluation (i.e., an intervention) vs. implementation (i.e., how it gets implemented) and what happens if each of those are effective or not effective
| intervention – “what” gets implementation | |||
| effective | not effective | ||
| implementation – “how” it gets implemented | effective | actual benefits | poor outcomes |
| not effective |
|
|
|

- the more complex an intervention is, the more attention needs to be paid to implementation
- the most difficult part of implementation is the changes in roles and relationships (i.e., behavioural changes)
- change is a process, not an event
- people don’t like to be told to change – you need to situate new behaviours in relevant history and saliency
- understand different actors’ motivations for behaviour change
- when you have multi-site projects/programs, you will have variation in implementation (i.e. how an intervention actually get implemented at different sites (even though you are implementing the same intervention at the different sites)
- why don’t people include context-sensitivity in complex intervention design?
- command and control culture (a lack of trust in the front lines)
- structural limitations on processing and responding to large amounts of data with nuanced implications
- epistemologies, especially in the health sector (in the health sector, people often think that they just find a pill/needle/surgery that is proven to work in an RCT and you just need to make that available and people will use it, despite evidence that just pushing out interventions does not actually get people to use them)
- there are profound differences between program designers and users/implementers of the program – evaluators can be a “translator” between the two.
- evaluators can ask the challenging questions
- our worldview is often different from program implementers and we can bring our insights
- continuous quality improvement (CQI): “the continuous use of data to inform decision making about intervention adaptations and about additional implementation supports (e.g., training, coaching, change to administrative processes, policies, or systems) needed to improve both implementation of the intervention and the outcomes associated with the intervention” (Wade)
- ignores the idea of “if it ain’t broke, don’t fix it”
- uses ongoing experimentation to improves processes (not about improving/”fixing” people) – e.g., Plan-Do-Study-Act (PDSA) cycles
- small incremental changes
- most effective when it’s a routine part of the way people work
- CQI evaluation questions:
- intention to reach:
- did the program reach its intended population?
- how well is it reaching those who would most benefit from it? (e.g., high risk groups, location/age/gender/SES)
- implementation:
- to what extent is the program delivered as intended? [this assumes that the way the program is designed is actually appropriate for the setting; sometimes programs are shown to be effective in one context but aren’t actually effective in a different context. Similarly, how to implement may work well in one context but not in another context]
- impact on outcomes:
- what changes in status, attitudes, skills, behaviours, etc. resulted from the intervention?
- intention to reach:
Evaluation in Aboriginal Communities
- There are many similarities between Australia and Canada with respect to Aboriginal people: a history of colonization, systematic discrimination, and ongoing oppression; A history of an imposition of “solutions” on community via programs, service delivery models, and evaluation methods; these are imposed by privileged white voices and they often harm Aboriginal communities and people rather than helping.
- Aboriginal communities prefer:
- self- determination
- two-way learning
- participating
- capacity-building – evaluations should not be about someone coming in and taking from the community
- include an Aboriginal worldview
- develop a shared understanding of what partnership really means
- Evaluation should be ongoing
- Evaluators should be facilitators, should be respectful, should understand community capacity within the context of local values/norms
- Trauma-informed, as communities have experienced colonial violence
- Often evaluations do not allow the time needed to do the work that is needed to conduct evaluation in a respectful way that gets useful information
- Communities need to have confidence in evaluations = confidence that evaluators will hear the whole story and report it ethically, and evaluations will be useful to the community and be done respectfully with the community
Systems Thinking
- “You don’t have to be a systems theorist to be a systems thinker” (Noga). You can use systems thinking as a paradigm/worldview, without having to go into the whole theory. [This reminded me of Jonathan Morrell’s talk at the CES conference]
- System = elements + links between the elements + boundary.
- Without the links between the elements, it’s just a collection.
- Boundaries can be physical, political, financial, etc. They may also be contested (not everyone may agree as to what the boundaries of a given system are). Determining the boundaries = deciding what’s in, what’s out, and what’s considered important; it’s an ethical, moral, and political decision.
- A program always has a mental model (someone believes there is problem and the program is a way to solve it), even if they haven’t articulated it.
- Evaluators investigate/describe:
- the program
- assumptions
- mental models
- stakeholders and their stakes (see Ladder Diagram in the Tips & Tools section below)
- As an evaluator, look for leverage points the program is using. Are they working? Could their be better ones?
- Evaluators investigate/describe:
- Interrelationships are what make a system a system instead of just a collection; they create:
- outcomes
- but also barriers, detours
- function & dysfunction
- emergent patterns & trends
- Complex systems are unpredictable (the program can have hoped-for or intended outcomes, but can’t necessarily predict things with any certainty).
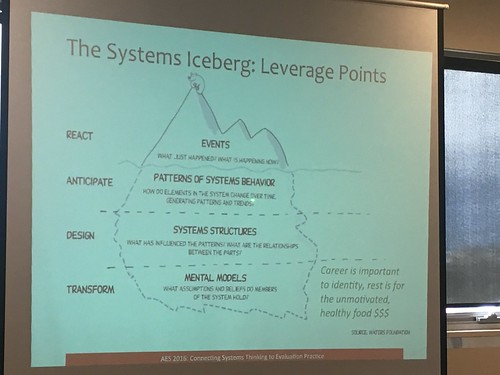
- The Systems Iceberg: Mental Models (what is the problem and how do we think we can solve it?), whether explicit or implicit, cause us to design structures, that in turn influence patterns of systems behaviour, which lead to events, which are what we tend to observe.
- e.g., you get a cold (event), because you haven’t been eating or sleeping well (behaviour), due to poor access to nutritious food and work stress (structures), work stress affects you because your career is important to your identity (so a threat to your career threatens your identity) and you believe resting = laziness.
- When you are evaluating a system, start at the top: what events happened? what patterns of behaviour led to those events? what structures lead to those patterns? what mental models/assumptions lead to those structure being developed in the first place.
- If you are designing a program, start at the bottom and work up! (Make your mental models explicit so you can make your design more intentional).
- Can use the iceberg conceptually as you investigate the program – e.g., build it into interview questions (ask about what happened, then ask questions to find patterns, questions to uncover mental models)
- interviews are a good way to get to mental models
- artifacts and observations are good ways to get to system structures
- observations and interviews are good way to get to patterns of behaviour and events.
- Complex Adaptive Systems: “self-organization of complex entities, across scales of space, time, and organizational complexity. Process is dynamical and continuously unfolding. System is poised for change and adaptation” (Noga slide deck, 2016)
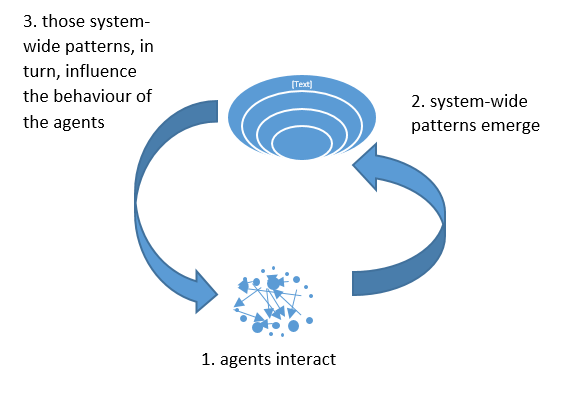
- Think of the above diagram as more of a spiral than a circle.
- e.g., 1. more women are single mothers and have to work, and more women choose to enter workface –> 2. policies re: childcare, tax credits for daycare/employers create daycares in response to more women in the workforce –> 3. supported childcare –> 1. new agent actions (e.g., even more women join the workforce as the new policies make it easier to do s0) and so on
- With CASs, expect surprises – so you need to plan for them (e.g., do you have a process in place to renegotiate what data is being collected in response to changes?)
- Wicked Problem truly resist a solution and every intervention into the wicked problem has an effect (so you can’t just pilot an intervention like you would for a normal problem, as the pilot itself will change the situation so doing that intervention again may not have the same effect as the starting point would be different; plus, the effect of the next intervention will be affected by the effect of the prior intervention; examples include: poverty, obesity epidemic, climate change, education (e.g. what do children need to know in the 21st century and how do we teach it to them?) – wicked problems interact with each other and that makes things even more complex (e.g., effects of climate change on those in poverty).
- Take home messages from Jan on Systems Thinking:
- be intentional – use systems thinking when it makes sense, use tools when they make sense
- document boundaries and perspectives
- our job as evaluators is to surface the story that the system is telling
Complexity
- some common approaches to complexity that don’t work
- careful planning doesn’t work in situations of uncertainty (because how can you plan for the unknown?)
- reliance on monitoring & evaluation (M&E) plans with high level annual reviews to guide implementation and oversight by higher ups who don’t have understanding of, or influence at, the front lines)
- emphasis on celebrating successes rather than learning from failures
- use of short timeframes and rigid budgets to reduce risk (it actually increases risk of ineffective interventions)
- instead we need:
- more regular reviews/active monitoring (which requires lots of resources; and we need to make sure it doesn’t become excessively structured)
- determine where the bottlenecks for adoption are and delegate responsibility to that level, giving lots of local autonomy, coaching, foster self-organization (need decision making at the lower levels)
- learn from good pilots and then use that to inform expansion (but also need to study how that expansion goes – can’t assume it will go the same way as the pilot)
- payment by results gives responsibility to the implementing agencies/communities to what they want to do, but:
- the outcomes need to be the correct ones
- the outcomes need to be verifiable [because this can easily be gamed, where people work to change the measured outcomes, not necessarily the underlying thing you are trying to change]
- modeling likely scenarios during design and at critical junctures using:
- human-centred design
- agent-based modeling
- complex system modeling
- all approaches need insight from evaluation
- often when higher ups look at indicators, things seem simple (indicators alone do not reveal the complexity that occurs on the ground)
Innovation
- In the session by Plant, Cooper, & Warth, they discussed innovation in healthcare in BC and New South Wales. In the BC context, “innovation” is usually focused on something that “creates value”, whereas in NSW it’s more about “something new” (even if it’s just new to you)
- a lively group discussion brought up some interesting points:
- innovation happens on the ground, so a top down approach to “mandate” innovation doesn’t really work
- innovation is a process, so the evaluation of innovation should be an evaluation of the process (rather than the product of the innovation) [though wouldn’t this depend on the evaluation question? e.g., if the evaluation question is “was the outcome of this program to support innovation worth the investment?”]
- innovation is challenging in a risk-averse setting like healthcare, as innovation requires risk taking as you don’t know if it’s going to work
- evaluation can have a role in supporting innovation when:
- proximity – there is a clear line of sight between activities and outcomes
- purpose – when a learning purpose is valued by the client
- evaluation is embedded in the planning cycle (using evaluative thinking/an evaluative mindset to inform planning)
- evaluator skills needed for evaluation to drive/support innovation:
- political nous (a.k.a. political savvy) – situational/reflexive practice competencies
- context knowledge – i.e., knows the health system
- content knowledge – i.e., specific to the area of innovation
- factors that limit evaluation’s role:
- political/leadership barriers & decision cycles
- innovation overload
- time frames
- a “KPI mindset” – i.e., inappropriate outcome measurement; the use of evaluation resources for measurement rather than doing deep dives and garnering nuanced understanding
- how do we counter the “KPI mindset”? The evaluation approach is different – e.g., you start with a question and then ask what data will provide the evidence required to answer that question (rather than starting with indicators – and assuming you know the right indicators to monitor)? (And that data might be qualitative!)
Cognitive Bias
- cognitive bias = “habits of thought that often lead to erroneous findings and incorrect conclusions” (McKenzie)
- e.g., framing effect: how you frame data affects how people react to it. E.g., if people are told a procedure has a 90% survival rate they are more likely to agree to it than if you say it has a 10% mortality rate. Thus, even though these mean the same thing, the way it’s framed affects the decision people make based on the evidence.
- e.g., anchoring effect: naming a number can affect what people expect, E.g., if you ask one group “Did Ghandi die before or after the age of 5?” and a second group “”Did Ghandi die before or after the age of 140?”, and then you ask people to guess what age he actually died, the second group will guess higher than the first group. This happens even though by 5 and 140 are obviously wrong – but they “anchor” a person’s thoughts to be closer to that first number they heard.
- there are tonnes more cognitive biases [Wikipedia has a giant list!]
- even when we are doing a conscious reasoning process, we are still drawing on our subconscious, including biases
- we like to believe that we make good and rational decisions, so it can be hard to accept that our thoughts are biased like this (and hard to see past our biases, even when we are aware of them)
- there is not much research on cognitive bias in evaluators, but research does show that evaluators :
- vary in the decisions they make
- vary in the processes they use to make decisions
- tend to choose familiar methods
- are influenced by their attitudes and beliefs
- change their decision making with experience (becoming more flexible)
- write reports without showing their evaluative reasoning
- some strategies to address bias:
- conduct a “pre-mortem” – during planning, think of all the ways that the evaluation could go wrong (helps to reduce planning bias)
- take the outside view (try to be less narrowly focused from only your own perspective)
- consult widely (look for disconfirming evidence, because we all have confirmation bias – i.e., paying more attention to those things that support what we already believe than those things that go against it)
- mentoring (it’s hard to see our own biases, even for people who are experts in bias!, but we can more easily see other people’s biases)
- make decisions explicit (i.e., explain how you decided something – e.g., how did you decide what’s in scope or out of scope? how did you decide what’s considered good vs. bad performance? This can help surface bias)
- reflecting on our own practice (e.g., deep introspection, cultural awareness, political consciousness, thinking about how we think, inquiring into our own thought patterns) needs to happen at points of decision and needs to be a regular part of our practice
- 10 minutes of mindfulness per day can decrease bias (compare that with the hours per day of mindfulness for many weeks that are required to get the brain changes needed for health benefits)
- some audience suggestions/comments:
- have other evaluators look at our work to look for bias (it’s easier to see other people’s bias than our own)
- we are talking about bias as if there is “one truth”, but there are multiple realities, so sometimes we misuse the word bias
Design Thinking

- model from the Stanford Design School:
| empathize→ | define→ | ideate→ | prototype→ | test→ | learn |
understand the experience of the user |
define the problem from the user’s perspective |
explore lots of ideas (divergent thinking) and then narrow them |
reduce options to best options → experience them |
|
can scale your learnings (e.g., to other projects, other users, other geographies)[the speaker added this one to the model] |
- model is shown as linear, but it is really iterative
Misc.
- In a session on evaluation standards, there was some good discussion on balancing the benefits of professionalizing evaluation (e.g., helps provide some level of confidence in evaluation if we have standards to adhere to and helps prevent someone who really doesn’t know what they are doing from going around claiming to do evaluation and making a bad name for the field when they do poor work) with the disadvantages (e.g., it can be elitist by keeping out people who have valuable things to contribute to evaluation but don’t have the “right” education or experience; can stifle innovation; can lead to evaluators working to meet the needs of peer reviewers rather than the needs of the client). There was also discussion about how commissioners of evaluation can lead to some issues with the quality of an evaluation by their determinations of scope, schedule, and/or budget).
- John Owen gave an interesting “history of evaluation” in his keynote talk on Day 2. An abridged version:
- pre-1950 – evaluation as we know it didn’t exist
- pre-1960: Tyler, Lewin, Lazarfield in USA (If you had objectives for your program and measured them, then you could say if a program “worked” or not)
- 1960s: with the “Great Society” in the US, there was more government intervention to meet the needs of the people and the government wanted to know if their interventions worked/was their money being spent wisely (accountability purpose of evaluation).
- 1967 – academics had become interested in evaluation. Theory of Evaluation as being a judgement of merit/worth. Michael Scriven (an Australian) contributed the notion of “valuing”, which isn’t necessarily part of other social sciences.
- 1980s onward – an expansion of the evaluation landscape (e.g., to influence programs being developed/underway; to inform decision making)
- currently – a big focus on the professionalization
- Katheryn Newcomer also presented a brief summary of evaluation history:
- 1960s: “effectiveness”
- 1980s: outcomes
- 1990s: results-based
- 2000s: evidence-based
- Words:
- Newcomer notes that Scriven advocates the use of the term “program impactees” rather than “beneficiaries” because we don’t know if the program recipients will actually receive benefits [though to me “impactees” suggests anyone who might be affected by the program, not just the program users (which is usually what people are talking about when they say “beneficiaries”). But I can totally appreciate the point that saying “program beneficiaries” is biased in that it pre-supposes the program users get a benefit. I usually just say “program users”/]
- “Pracademic”- a practical (or practitioner) academic (Newcomer)
- In discussing evaluating a complex initiative, Gilbert noted that they choose to focus their evaluation only on some areas and no one has criticized them for prioritizing some parts over other parts [I found this an interesting comment as I’m concerned on my project that if some parts aren’t evaluated, it would be easy to criticize that the project on the whole was not evaluated]. She also noted that they had really rich findings and that there was a triangulation where findings on one focus area complimented findings on another focus area
Tips and Tools
Throughout the conference, a number of speakers shared different tips and tools that might be useful in evaluation.
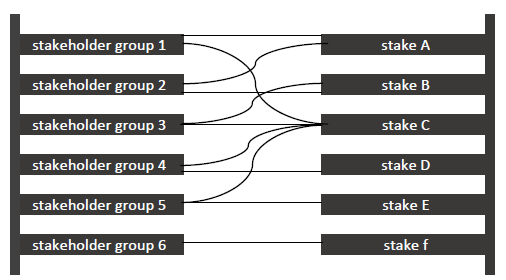
Ladder diagram for mapping stakeholders and stakes:
- list all the stakeholders
- ask them each “what is the purpose of this program?” (those are the “stakes”)
- draw lines between the stakeholders and the stakes
- allows you to see:
- stakes that are held by multiple groups
- stakes that only have one stakeholder (sometimes these outliers are really important! e.g., for an after-school program in which Noga did this where they were experiencing poor attendance/high drop out rates, the kids were the only stakeholders that noted “fun” as a purpose of the program. That was the missing ingredient to why kids weren’t showing up – the program planners and deliverers were focused on things like safety and nutrition, but hadn’t thought about making it fun!)
Program Models (e.g., logic models)
- A model is a representation of the program:
- at a certain time
- from a certain perspective
- Can look at the model over time, reviewing what has changed or not changed (and what insights does that give us about the program?)
Causal Loop Diagrams
- A diagram that shows connections and interrelationships among elements
- Difficult to make and to use (would probably want a systems dynamics expert to assist with this if you were to make/use one)
- Here’s an example of one (from Wikipedia):


“Low Tech Social Networking”
- an ice breaker activity that you can use to see the mental models people are working with and to start to see connections in the network
- ask participants to do the following on a sheet of paper:

Exploring Boundaries Activities
- a bunch of toy animals were provided and every participant was told to pick any 4 they want

- in table groups, participants were asked to find how many different ways they can be groups
- e.g., some of the groups we came up with were grouping by biological taxonomy (e.g., amphibians, reptiles, mammals, birds), by land-based/water-based animals, by number of legs, by colour, in order of size
- this allows you to illustrate how boundaries are constructed by our choices (within certain constraints) – how and why people chose the boundaries they do are interesting questions to think about
Postcard Activity
- Participants are all asked to pick 3 postcards from a pile
- Groups asked to make up a story using their cards. Each group tells their story to the whole crowd.
- Debrief with the groups:
- You are constrained by the cards each person brought in (and a perspective was brought by each person choosing the cards)
- You find links
- You make choices
- Did you fit the cards to a narrative you wanted?
- Did the story emerge from the cards?
- There is no one right way to do it
- A different group could come up with a totally different story from the same cards (different perspectives)
- When you are evaluating, the program is the story. You want to understand how the story came to be. What was the process? What perspectives are reflected?
- Bonus idea: You could use this postcard activity as a data collection tool – ask people to write the anticipated story before you start, then again midway through, then at the end. Which of the things you expected held? Which didn’t? Why did things change? What was surprising?
Snowcarding
- ask a question (e.g., what are we going to do about juvenile delinquency in this town?)
- everyone writes as many ideas as they can think of one sticky notes (one idea per sticky note) and cover the wall with them
- group then themes the ideas together
- then ask the group “What are you going to do with these ideas?”
Game to Demo the Concept of Self-Organization
- each person is assigned a “reference person” and they are told they are not allowed to be within 3 ft of that person
- everyone is told to go mingle in the room
- some people are assigned the same “reference person” – they will end up clumping together as they all try to avoid that person – this is an example of an emerging, self-organized pattern (a bunch of individual agents acting on their own reasons end up forming patterns)
Creating Personas
- a tool commonly used in marketing where you craft a character to represent market segments (or, in the case of evaluation, stakeholder)
- can use this to help with your stakeholder mapping and evaluation planning
- e.g., create a persona of Max the Manager, Freda the front-line staff, Clarence the Client, etc. – what are their needs/wants/constraints/etc.? how can these characters help inform your planning?
- avoid stereotyping (base on real data/experience as much as possible) and avoid creating “elastic” personas (i.e., contorting the character to incorporate everything you’d want in someone in that role)
- design for the majority, but don’t forget the outliers
Participant Journey Mapping
- a visual representation of an individual’s perspectives of their interactions and relationships with a organization/service/product
- can use this to map out the “activities” for a logic model
- focus on the user’s experience (what the user experiences can be quite different from what the program designer/administrator thinks the experience is)
- think about:
- emotional side – high points/low points; happiness/frustration; pain points
- time/phases – before/during/after the experience
- touch points and formats – e.g., online/offline; phone/F2F; real person/robot
- it’s about understanding the experience
- useful way to identify areas for improvement
- can be used during design or during implementation
- can be a communication tool
- can be an evaluation tool – e.g., map a user’s journey to see what was good/bad from their perspective and identify places to review more deeply/improve
Compendium Software
- free mapping software
- http://compendium.open.ac.uk/institute/about.htm
Things to Read:
- John Owen’s Book: Program Evaluation: Forms and Approaches is considered a seminal evaluation text in Australia. I haven’t read it yet, so I should really check it out!
- Peunte & Bender (2015) – Mindful Evaluation: Cultivating our ability to be reflexive and self-aware. Journal of Multidisciplinary Evaluation. Full-text available online.
- Moneyball for Government – a book, written by a bipartisan group, that “encourages government to use data, evidence and evaluation to drive policy and funding decisions”
- Mayne (2010). Building an evaluative culture: the key to effective evaluation and results management. The Canadian Journal of Program Evaluation. 24(2):1–30. Full-text available online.
- David Snowden’s cynafin. http://cognitive-edge.com/ [I’ve read this before, but think I should re-read it
Sessions I Presented:
-
Snow, M.E, Snow, N.L. (2016). Interactive logic models: Using design and technology to explore the effects of dynamic situations on program logic (presentation).
-
Snow, M.E, Cheng, J., Somlai-Maharjan, M. (2016). Navigating diverse and changing landscapes: Planning an evaluation of a clinical transformation and health information system implementation (poster).
Sessions I Attended:
-
Workshop: Connecting Systems Thinking to Evaluation Practice by Jan Noga. Sept 18, 2016.
-
Opening Keynote: Victoria Hovane – “Learning to make room”: Evaluation in Aboriginal communities
-
Concurrent session: Where do international ‘evaluation quality standards’ fit in the Australasian evaluation landscape? by Emma Williams
-
Concurrent session: Evaluation is dead. Long live evaluative thinking! by Jess Dart, Lyn Alderman, Duncan Rintoul
-
Concurrent session: Continuous Quality Improvement (CQI): Moving beyond point-in-time evaluation by Catherine Wade
-
Concurrent session: A Multi-student Evaluation Internship: three perspectives by Luke Regan, Ali Radomiljac, Ben Shipp, Rick Cummings
-
Concurrent session: Relationship advice for trial teams integrating qualitative inquiry alongside randomised controlled trials of complex interventions by Clancy Read
-
Day 2 Keynote: The landscape of evaluation theory: Exploring the contributions of Australasian evaluators by John Owen
-
Concurrent session: Evolution of the evaluation approach to the Local Prevention Program by Matt Healey, Manuel Peeters
-
Concurrent session: The landscape of using rubrics as an evaluation-specific methodology in program evaluation by Krystin Martens
-
Concurrent session: Beyond bias: Using new insights to improve evaluation practice by Julia McKenzie
-
Concurrent session: Program Logics: Using them effectively to create a roadmap in complex policy and program landscapes by Karen Edwards, Karen Gardner, Gawaine Powell Davies, Caitlin Francis, Rebecca Jessop, Julia Schulz, Mark Harris
-
AES Fellows’ Forum: Ethical Dilemmas in Evaluation Practice
-
Day 2 Closing Plenary: Balance, color, unity and other perspectives: a journey into the changing landscape in evaluation, Ziad Moussa
-
Day 3 Opening Keynote: The Organisational and Political Landscape for Evidence-informed Decision Making in Government by Kathryn Newcomer
-
Concurrent session: Effective Proactive Evaluation: How Can the Evidence Base Influence the Design of Complex Interventions? by John Owen, Ann Larson,Rick Cummings
-
Concurrent session: Applying design thinking to evaluation planning by Matt Healey, Dan Healy, Robyn Bowden
-
Concurrent session: A practical approach to program evaluation planning in the complex and changing landscape of government by Jenny Crisp
-
Concurrent session: Evaluating complexity and managing complex evaluations by Kate Gilbert, Vanessa Hood, Stefan Kaufman, Jessica Kenway
-
Closing Keynote: The role of evaluative thinking in design by John Gargani
Image credits:
-
Causal Loop Diagram is from Wikipedia.
-
The other images are ones I created, adapting from slides I saw at the conference, or photos that I took.
Footnotes
| ↑1 | E.g., while Owen used “adoption” to refer to the “adoption” (or choosing) of a program to implement, I’ve seen others use “adoption” to refer to individuals (e.g., to what extend individuals “adopt” (or enact) the part of their program they are intended to enact). |
|---|


{kind=link}